There are many facets to consider in the implementation of even the most basic Software Configuration Management (SCM). For Java, with its import mechanism, these simple goals often become unmanageable when the source code tree grows beyond a certain point of complexity. This is mainly due to the reticulate interdependencies that arise within the source code tree as it evolves. Also, because code is seldom (if ever) retired, the codebase continues to grow, causing this network to become increasingly complicated over time.
In this article I would like to explore both the evolution of the typical Java source code tree as well as articulate the underlying relationships that make even basic Java SCM problematic. I will also suggest a simple way to manage source code relationships to meet basic SCM goals.
Understanding these topics will allow Java development shops to begin implementing simple, yet effective SCM systems that balance requisite process with unencumbered development, testing, and operational deployment.
By requisite process I mean staying just a couple steps ahead of SCM-related firefighting while remaining unencumbered by laborious and/or unnecessary processes.
I'd like to articulate what I consider to be simple goals of SCM, as well as why these become so difficult to achieve so early on in the development life-cycle. The primary areas of interest are:
- Maintaining source code under revision control
- Managing code dependencies and third-party library dependencies
- Managing builds and build dependencies
- Managing dependencies on third-party JARs
Beyond a certain range of complexity (usually a few hundred total source files depending on the skill of your developers and how quickly they're being asked to churn out code), the reticulate interdependencies within the code are unable to be unwrapped. This is to say that the large number of interdependencies introduced by import statements cause artificial dependencies when trying to add features, build, branch, release, and test your code.
More specifically:
- Building a sub-tree causes the compilation of every source code file in your source tree due to circular dependencies. This results in extremely lengthy build times (O[several hours] for some projects I've seen).
- No source code is free to move along under it's own development cycle, meaning, you might need to build a sub-branch N times per day, and another only M times per month, but because they have import interdependencies, they are both built at the maximum (required) rate.
- Branching and merging is extremely time-consuming and complex and can introduce significant developer downtime, mostly due to the large number of source files that must be considered.
- Releasing code to operations is very difficult, as you have to push every Java class file upon release.
- Testing is more difficult, if not impossible, since it is more difficult to isolate sub-branches of code to understand their functionality. It is also more difficult to write a testing harness for a subbranch (e.g.: using JUnit).
Most current source code management tools deal with navigating source hierarchies and finding objects and methods. These are great problems to solve, but not ones that we're primarily interested in solving (JavaDeps comes relatively close in that it helps to discover some compilation dependencies that go unnoticed by some compilers).
Similarly, many revision control systems (RCS) provide check-in, check-out, branch and merge capability, but none address source code tree structure and how to manage the requisite dependencies involved.
The target audience is developers, testers, and operational support staff who are interested in taking the necessary steps to actively manage their Java-based projects in terms of building source code for test and operational deployment, developing multiple versions of a product or service in parallel, and replicating operational, test, and development environments to reproduce unexpected behavior and fix bugs.
Large numbers of source Java files is in the range [500..10k] with large numbers of dependent third-party JARs is in the range [50..1k]. All told, we're talking about a set of development projects that have O[50k] total document and code artifacts... not very big, but large enough such that it's worth examining how the codebase evolves and how to keep it from turning into a liability instead of the asset it is intended to be.
Due to its complex nature, this topic is extremely expansive -- too large to be covered in a single article. This article will start by covering the basics of source code management and builds and will finish by touching on the topics of managing deployments and documentation. Future areas for discussion include managing properties files, building WAR files, and managing build tools.
Every Java shop I've ever worked in has followed an eerily similar evolutionary path as far as it's Java source code is concerned:
- Start the root branch off by creating Java package com.mycompany
- Begin to populate the source tree with a layer of utility and/or base classes, many of them the usual suspects like com.mycompany.db, com.mycompany.utils, com.mycompany.regexp, com.mycompany.xml, etc.
- Continue to populate this source tree with a set of servlets, beans, data access, and JSPs that depend on the set of common classes (the aforementioned usual suspects).
This approach is extremely intuitive, and works for a while; for about as long as the codebase is simple enough that dependencies between distinct packages are well understood.
The first dependencies introduced are usually servlets, beans, and JSPs importing common/shared utility classes. These dependencies are distinct, simple, and well understood. However soon thereafter, more complex references are introduced as developers try to reuse as much code as possible while minimizing the time they spend repackaging code. A servlet from one package begins to look like a utility to another package and is subsequently imported. This type of import can create a circular reference (shown below in Figure 1) between source code files and sets the stage to make even simple SCM prohibitively complex.
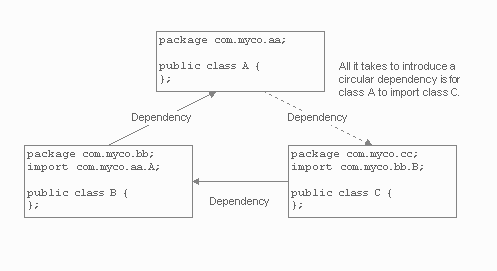
Figure 1: Circular Dependencies via Javas import Statement
Introducing circular references in Java is surprisingly easy and extremely common, though interestingly enough I've never actually heard of a developer admitting to such a practice. Understanding these relationships, plus your source code's dependencies to third-party JAR files, are keys to having a modular, branchable, buildable, testable, and deployable codebase.
The first step in decoupling direct source code dependencies is to partition your source code into components.
A component is a set of Java packages that together provide a specific set of functionality and additionally have their own development cycle. It doesn't matter whether it's 1 package or 20, 1 source file or 200 source files (though using any more than a few hundred source files in 1 component will bring you right back where you started in terms of problematic source code management). By having their own development cycle I mean that, relative to the other components, the source files need to be built/tested/deployed N times/day while other source code needs to go through this cycle M times/day.
Partitioning source code into components will become fairly intuitive with a few examples, which are presented below.
Example 1: Utils make great components because they are shared by so many other source files and therefore end up as a dependency on a lot of files. This also causes them to have a quicker dev cycle (and therefore quicker build turn-around) than most other source code. Create one component for all of your utils, or partition them further into multiple components, e.g.:
|
or: |
|
Example 2: Database access classes can be grouped into separate components. For multiple database servers, use multiple data access components, tying each schema to a component 1:1. This works out nicely to both handle schema changes and to help manage dependencies of a component on multiple database servers.
| Component | Java Packages |
|---|---|
| userdata | com.mycompany.db.users |
| customerdata | com.mycompany.db.customers |
| inventorydata | com.mycompany.db.inventory |
Example 3: A set of JSPs or servlets that together provide a specific set of functionality should be a separate component. This could be a data-entry application, or a data-feed reader, or an administrative UI for one of your internal systems. Because these types of components have their own requirements and delivery dates, and the requirements change, they end up on their own development schedule, so it makes sense to create a component here.
| Component | Java Packages |
|---|---|
| AdminUI | com.mycompany.servlet.admin |
| DataEntry |
com.mycompany.servlet.dataentry com.mycompany.servlet.dataentry.parser |
| DataService |
com.mycompany.servlet.dataservice com.mycompany.servlet.dataservice.cache com.mycompany.servlet.dataservice.interface com.mycompany.dataservice.factory com.mycompany.dataservice.threadpool |
In total you could end up with as many as several hundred components, each with anywhere between 10 and perhaps 350 source files. Although it looks complicated to partition your source code, it's actually really easy (the difficult part is getting your builds started).
All of this source code needs to be checked into a revision control system (RCS). Any/all RCS syntax in this article will be in reference to Perforce, as it is has many features[1] that make SCM very simple.
In perforce parlance, the component source code is checked into location:
//depot/components/<component_name>/src
e.g.:
//depot/components/FileUtils/src/com/mycompany/...
//depot/components/DataParser/src
//depot/components/UserData/src
Builds, branches, and documentation is also partitioned under each component for RCS:
//depot/components/<component_name>/src
//depot/components/<component_name>/branch
//depot/components/<component_name>/builds
//depot/components/<component_name>/docs
The other source for build dependencies are between your source code and JARs provided by a third-party.
This necessitates active management of these files to keep on top of their multiple versions and frequent name collisions. It's very easy to impede the progress of debugging and building through mismanagement of third-party JARs and ZIPs (e.g.: opening up JARs manually to try to find a version number to find out what you built against, or what version you have in production), and yet remarkably simple to organize them intuitively and efficiently.
Because successive versions of third-party JARs sometimes result in name collisions, it's necessary to use the version numbers to maintain them under RCS. In perforce, the JARs might look like so (using the JDK and JSDK as examples):
//depot/jars/jdk/1.2.2/rt.jar
//depot/jars/jdk/1.3.0/rt.jar
//depot/jars/jdk/1.3.1/rt.jar
//depot/jars/jsdk/2.0/jsdk.jar
//depot/jars/jsdk/2.1/server.jar
//depot/jars/jsdk/2.1/servlet.jar
//depot/jars/jsdk/2.2/servlet.jar
This versioning scheme allows components that might depend on the 2.1 version of servlet.jar to reside next to components that might depend on the 2.2 version of this file. Both components can be built and deployed in parallel and their dependencies tracked accordingly.
This approach also has the added bonus of allowing for any client that has access to your RCS server to be able to run builds, as every server has access to the requisite JARs via RCS.
Now that your source code is partitioned and third-party JARs are under RCS, it's time to start building. Build requirements are very simple:
- A build for one component may only execute against that component's source code. All other build dependencies must be linked through either other components builds or third-party JAR/ZIP files. In short, a component build may not execute against any source code other than it's own.
- Results of builds (JARs) must be under RCS.
- Source code needs to be labeled with the build number, so there is a link between a build JAR and the source code that produced that JAR/WAR. This implies that given any JAR for any component, the original set of source code can be located.
- The dependencies for a deployment (a set of JARS that are deployed together into QA/dev for testing/ production) must be under revision control; meaning, the list of dependent JARs for a build of a component must be under revision control.
This first component built must be entirely self-contained, which means it can be built using only it's own source code and (optionally) third-party JAR files. Components built this way are seed builds and start your build process. Build each of these components one at a time by compiling their Java source, JARring up the resultant class files, and checking these JARs into your RCS (build scripts should do all of this for you).
If you cannot isolate a component so that it is entirely self-contained, you can either repackage your source code (not often done due to time constraints) or generate an invalid build[2] so you can begin to generate seed builds.
A high-level overview of a build involves the following steps:
- Sync up source code and third-party JARs from your RCS to your local machine.
- Make sure your target build number hasn't been built already.
- Set up your CLASSPATH, which contains three sets of entries:
- The path to the root of the component's source
- The paths to other JAR files from other components
- The paths to requisite versions of third-party JAR files
- Execute make to build your source.
- JAR up the resultant class files, check this JAR into RCS.
- Generate a build summary file (containing the environment, date, etc), check this into RCS.
- Generate a label and stamp the source code for the build with the label.
Once you have all of your seed builds, begin to build those components that have only one level of dependence on other source code within your repository, meaning they can be built using only (a) their own source code (b) the seed JARs and (optionally) (c) third-party JARs. Build each of these components individually, JAR up their resultant class files, and check these JARs into RCS.
Once all of your one-level dependence builds are complete, it's open season to build the rest of your components, usually done in order of increasing number of dependencies. The goal is to make sure no component is compiled against any source code except it's own.
What you're effectively doing here is isolating like branches of Java code in sets of Java packages against changes in other branches of Java code (also grouped in Java packages). This is probably the most important aspect of the build strategy. What this allows stakeholders of your SCM system to do is to isolate, and therefore understand, the dependencies between source code and JARS, and therefore both trace back any build to the source code that was used to generate the build as well as replicate an environment by easily replicating the JARs used to construct the environment.
Equally important is that the source code for a component is associated with it's build JAR via a label, so it's easy to trace any class file you have in production back to it's source files, and then from there to trace other dependent components class files back to their corresponding source code.
This method of organizing your builds also frees up any components that share a dependency on a common component (e.g.: utils). The common component is now on it's own development cycle, so it can be iterate through many build cycles while allowing dependent components to migrate to newer builds when it makes the most sense. Said another way, it allows for independent/parallel development of components that both have a dependency on a single, shared component.
- Component #1: Utils. No dependencies. Build it against it's own Java source code to generate a JAR file containing the resultant .class files.
- Component #2: DataParser. Depends on a previous build of the Utils component, as well as a third-party JAR called xerces.jar (v1.4.1). Built it against (a) it's own source code (b) a previous Utils component build and (c) the xerces.jar file from xerces v1.4.1 (in perforce, this would come from //depot/lib/xerces/1.4.1/xerces.jar)
- Component #3: DataCaptureUI. Depends on a previous build of DataParser, a previous build of Utils, and a 3rd-party JAR called servlet.jar (v2.0). Build it against (a) it's own source code (b) a previous DataParser component build (c) a previous Utils component build and (d) the servlet.jar file from jsdk 2.0 (in perforce, from //depot/lib/jsdk/2.0/servlet.jar)
Note that because Component #3 depends on DataParser, and DataParser depends on xerces.jar, you'll need to add xerces.jar as a dependent JAR for the DataCaptureUI build.
The above set of builds and dependencies is shown in the following figure:

Figure 2: Build Example with Dependencies
Managing source code dependencies is only the tip of the iceberg for comprehensive SCM. Other facets of SCM that fit into the component model include:
- Managing Deployments: A deployment is the set JAR, ZIP, WAR, and properties files that together allow the component to operate in it's designated environment (usually dev, test, or operations). Property and config files can be partitioned similar to source code, whereupon all component artifacts can be sync'd directly from your RCS server to their deployment server with deployment dependencies tested and well understood.
- Managing Documentation: Component documentation can be bundled with it's corresponding component under RCS and mapped to a mount-point on your Intranet server for automated publishing. Documentation management has a large number of implicit requirements involving availability, content, and versioning from release to release.
Partitioning Java source code into components and formalizing dependencies will provide several key benefits for your Java-based projects, some of which are implicit thus far:
- Ability to parallelize development of projects that share common a codebase.
- Ability to easily deploy to development, test, and operational environments.
- Ability to minimize the amount of code associated with a build/deployment.
- Eliminate confusion and name collisions due to third-party JAR dependencies.
- Reproduce deployment environments to help reproduce problems (and then eliminate them).
- Ability to retire code and branches of code when a component is retired.
[1] Perforce is cross-platform, has both console and windows clients, provides flexible/powerful mapping between a source code repository (the "depot") and a client of that repository, and allows for intuitive branching, merging, and labeling, all of which is required to manage your source code.
[2] An invalid build is when a component is built against it's own source code plus the source code of another component. Sometimes it's impossible to isolate even one component so it is self-contained, whereupon you'll need to build it against multiple components' source code to get started. After this initial build, you'll be able to build it against it's own source code and JARs created from this first build.